A Practical Guide to Downtime Classification
Why This Is the First Step

Most production lines already track downtime. There are reports, shift logs, and in many cases dashboards that show where time was lost.Despite this, many teams struggle to improve performance in a consistent way. The issue is rarely the lack of data. It is the lack of structure behind that data.When downtime is not classified in a clear and consistent way, it becomes difficult to understand what is really happening on the line. Different shifts describe the same issue differently, some events are grouped under generic labels, and short interruptions are often ignored. The result is a dataset that looks complete, but cannot support decisions.Before focusing on optimization, speed, or new investments, the first step is much simpler: making downtime data reliable and usable.Type your paragraph here
What Typically Goes Wrong
In practice, most downtime systems fail for the same reasons.
The classification logic is either too complex or too vague. Operators interpret categories differently. A significant share of downtime ends up under “other,” which provides no direction for improvement. At the same time, small and frequent stops are not consistently recorded, even though they often represent a meaningful loss.
This is not a technical problem - It is a structural one.
As highlighted by organizations such as Lean Enterprise Institute, continuous improvement relies on standardized definitions of losses. Without that standardization, even good data becomes difficult to act on.
What Good Classification Looks Like
A structured downtime approach is not complicated, but it must be consistent.
The first requirement is a clear and limited set of categories that are applied in the same way across all shifts and lines. The objective is not to capture every possible detail, but to ensure that recurring issues are always recorded under the same logic.
At the same time, generic categories such as “other” should be treated as temporary. If they remain a significant share of downtime, it is a clear indication that the classification is not precise enough.
Another critical point is the inclusion of short stops. These are often ignored because they are perceived as minor, but over the course of a shift they accumulate and can represent a significant share of lost capacity.
Once these elements are in place, the quality of the data improves quickly. Patterns begin to appear, and recurring issues become visible across shifts, products, and time periods.
From Data to Action

When downtime is structured correctly, the next step becomes straightforward.
Instead of trying to improve everything, teams can focus on the few causes that generate the majority of losses. This is a well-established principle in manufacturing, also reflected in analyses by McKinsey & Company, where a limited number of causes often drive most of the inefficiencies.
In practical terms, this means that improvement efforts become more focused and easier to execute. Teams can assign ownership, track results, and measure progress over time.
Without proper classification, this step is difficult. With it, it becomes a natural continuation of the process.
Where Indeex Fits
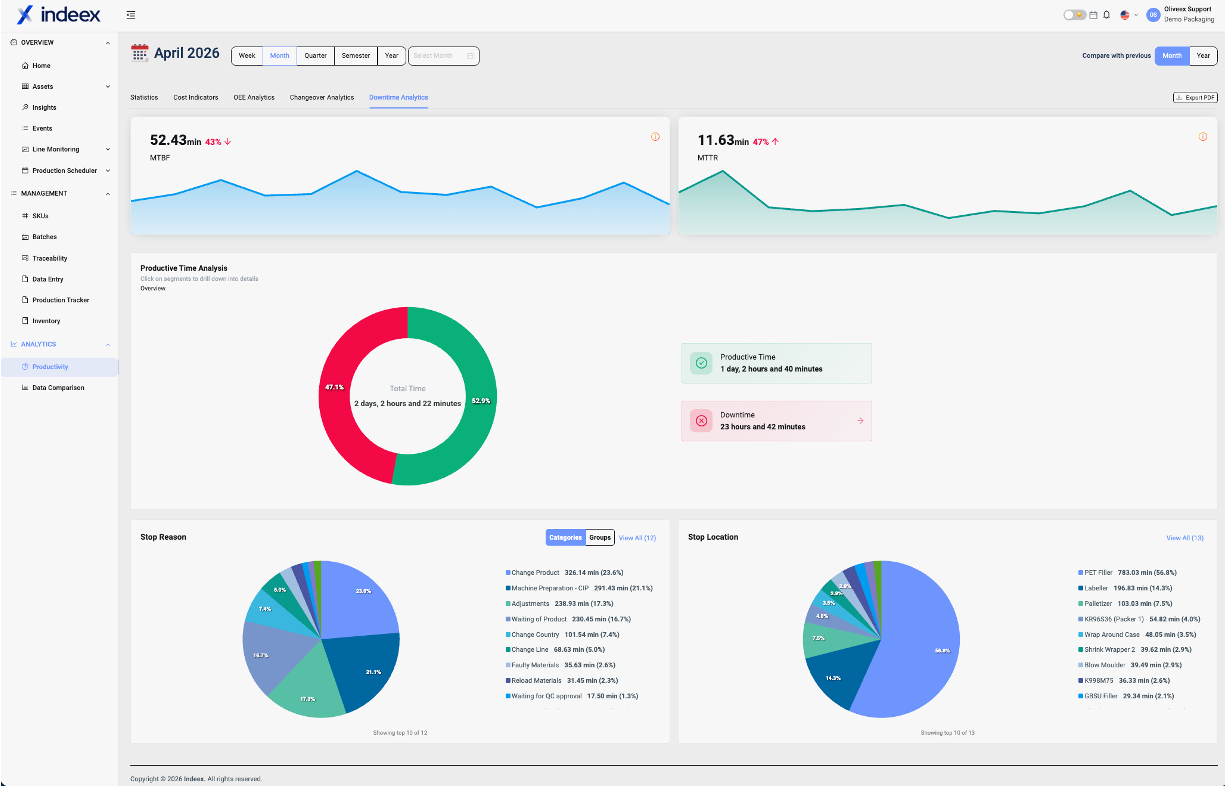
The challenge is not defining downtime categories. Most teams can do that relatively quickly.
The real difficulty is applying them consistently and ensuring that all relevant events are captured.
This is where Indeex is designed to support operations.Indeex connects directly to the production line and captures downtime automatically, including short stops that are often missed. This ensures that the dataset is complete and not dependent on manual recording.
At the same time, it applies a consistent classification structure across shifts, lines, and products. This removes the variability that typically comes from different interpretations and makes the data comparable and reliable.
Because the data is available in real time, teams are not limited to end-of-shift reports. They can see how downtime evolves during production, identify recurring issues early, and react faster.
More importantly, once downtime is fully captured and structured, it becomes possible to clearly identify the main losses and prioritize actions. This is why manufacturing teams across more than 10 countries are using Indeex today: not to collect more data, but to finally make their existing data actionable.
What You Can Expect

Improving downtime classification is one of the fastest ways to create impact on a production line.
In most cases, it leads to immediate visibility of previously unclear losses and allows teams to focus on a small number of high-impact issues. This typically results in faster decision-making and measurable improvements within a short period of time.
It is a low-effort step, but it changes how the entire improvement process works.
Closing
Improving performance does not start with complex initiatives.
It starts with clarity.
If downtime is not classified in a consistent and complete way, improvement will remain slow and based on assumptions. When it is, improvement becomes structured, measurable, and much easier to execute.
Next Step
If you are already tracking downtime but still struggle to clearly identify your main losses, it is worth reviewing how your data is captured and structured in practice.
We can walk you through a real production setup and show how downtime is automatically detected, classified, and translated into concrete actions.
